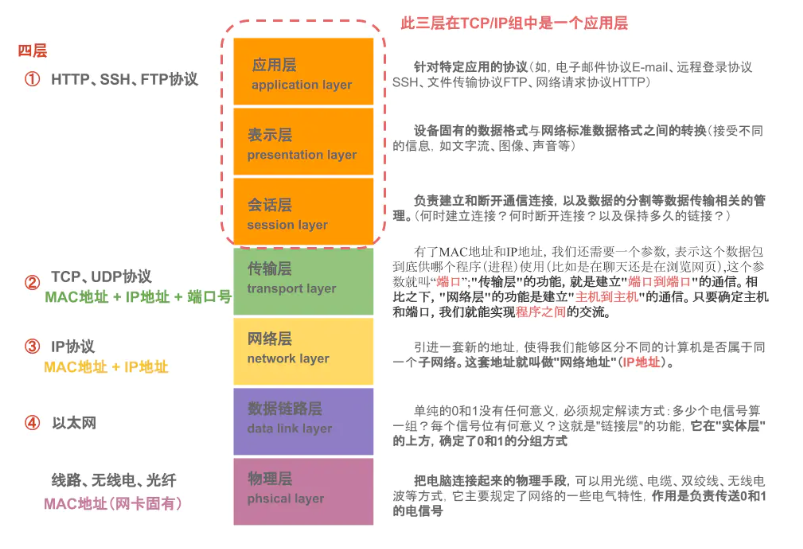
计算机网络
网络七层协议
引用网上的一张图,如侵权请联系我删除 😂
从输入 URL 到页面加载发生了什么
- 浏览器查找当前 URL 是否存在缓存,并比较缓存是否过期
- 根据 DNS 解析得到 IP 地址
- 建立 TCP 连接(3 次握手)
- HTTP 发请求
- 服务器处理请求,返回数据
- 渲染页面,构建 DOM 树
- 关闭 TCP 连接(4 次挥手)
HTTP
HTTP(HyperText Transfer Protocol),基于 TCP 实现的应用层协议。HTTP 是一个无状态的协议,即客户端和服务端之间不用建立持久的链接,当客户�端发送一个请求,服务端返回响应时,连接就被关闭了。
当请求一个 url 时www.baidu.com,首先DNS解析出该地址对应的 IP 地址,然后将相关信息封装成一个 HTTP 请求数据包。然后 TCP(三次握手)建立连接,连接成功后发送 HTTP 请求,服务端响应回来后,关闭 TCP 连接。如果浏览器或服务器在头部加入了Connection:keep-alive,那么 TCP 在发送完信息后仍然保存连接,这样可以减少 TCP 连接次数,能提升性能和服务器吞吐率,HTTP1.1 默认开启。
缺点
- 通行使用明文,不安全
- 不验证身份,可能遭遇伪装
- 无法验证报文完整性,可能遭遇篡改
前面提到了 HTTP 是一个无状态的协议,那如何让它拥有状态?
session 和 cookie
cookie(key/value 形式)
客户端返回 cookie 附在响应头中的Set-Cookie或者Set-Cookie2,cookie 保存在客户端,下次访问时连同 cookie 发送给服务端
cookie 的同源和跨域:
cookie 只关注域名,忽略协议和端口,意思是协议或者端口不同不属于跨域
session 机制(服务端维护的),基于 cookie 工作
session 和 sessionId(返回给客户端)
当客户端访问服务端时,首先检查请求中是否包括 sessionId。如果有,通过 sessionId 检索出对应 session 进行一系列操作。如果没有 sessionId,创建一个 session 以此对应的 sessionId 通过 cookie 存在客户端,客户端之后访问服务端时通过这个 sessionId 维护 HTTP 状态。
HTTPS
HTTPS = HTTP + TLS/SSL
经过加密的 HTTP,更加安全,利用 SSL/TLS 加密数据包;
TLS/SSL:安全传输层协议 Transport Layer Security
TSL/SSL涉及到三种算法:
- 散列函数 Hash:MD5, SHA1, SHA256(函数单向不可逆,加密传输信息以及信息摘要)
- 对称加密:AES-CBC, DES, 3DES, AES-GCM
- 非对称加密:RSA(分公钥和私钥)
TSL 工作方式:
首先使用非对称加密算法加密进行通信,服务端返回公钥并协商使用对称加密后的密钥对通信进行加密。
RSA 存在的隐患/缺点:
- 耗时过长
- 无法确保服务器身份(公钥是不是服务器返回的)的合法性(因为公钥不包含服务器信息),因为服务器分发公钥时可以被劫持
C(客户端)和 S(服务端)通信时,H(劫持者)截获了 S 与 C 的通信,H 将自己的公钥 pub_H 给了 C,当 C 向 S 发送请求时,实际上是使用 pub_H 加密的,这样 H 就能获取到 C 发送的消息了。这样原本属于 C 和 S 的通信现在就变成了 C 和 H 的通信了。
**解决方案:**引入第三方认证机构(证书 + 签名(防止服务端返回证书时被篡改)),验证公钥拥有者的信息然后颁发证书,简称 PKI体系
- S 向第三方机构提交公钥和公司相关信息
- CA(即三方认证机构)通过一系列渠道验证审核 S 信息的正确性
- 审核通过后,CA 向 S 签发证书,证书信息包括:S 的公钥、S 公司相关信息、签发机构 CA 的信息、有效时间、证书序列号(前面这些信息全是明文显示)。签名(使用散列函数计算公开的明文信息的信息摘要,然后用 CA 的私钥对信息摘要加密)
- C 向 S 发送请求,S 返回证书
- C 读取证书中的明文信息,采用相同的散列函数计算得到信息摘要,然后利用 CA 对应的公钥对签名进行解密,对比证书中的信息摘要来验证证书/公钥的合法性。
- 通过 hash 散列函数计算出信息摘要并使用 CA 提供的公钥对签名解密得到信息摘要,对比证书中的信息摘要来验证证书合法性
- Client 生成一个密钥 CPrivate, 并利用 Server 的公钥 SPublic 对 CPrivate 进行加密�传送给 Server
- Server 使用 SPrivate 对信息进行解密得到 CPrivate
- 之后的所有通信都依赖与 CPrivate
HTTP 请求方法
| 方法 | 描述 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体。 |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
GET 和 POST 的区别
GET
- 可被缓存
- 会保留在浏览器历史中
- 请求数据长度有限制
- 语意上用于取回数据
- 安全性较差
- 数据在 URL 中发送
POST
- 数据在消息体中发出不可见
- 不被缓存
- 不保留在浏览器历史中
- 请求数据长度不限制
- 比 GET 安全一些
- 语意上提交数据
常用状态码
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
| 状态码 | 描述 |
|---|---|
| 200 | 请求成功 |
| 204 | 无内容。服务器成功处理,但未返回内容 |
| 301 | 永久移动。请求的资源已被永久的移动到新 URI,返回信息会包括新的 URI,浏览器会自动定向到新 URI。今后任何新的请求都应使用新的 URI 代替 |
| 302 | 临时移动。与 301 类似。但资源只是临时被移动。客户端应继续使用原有 URI |
| 304 | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 400 | 客户端请求的语法错误,服务器无法理解 |
| 401 | 请求要求用户的身份认证 |
| 403 | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 500 | 服务器内部错误,无法完成请求 |
HTTP2
使用二进制传输数据,一个 TCP 连接上可以有任意多个流(stream),将响应分成了两个帧(frame): HEADERS、DATA
基于 HTTP1.1 存在的问�题
- TCP 连接数限制,对于同一个域名,浏览器只能同时创建 6-8 个 TCP 链接(各浏览器不同),且 TCP 连接成本较高(DNS、三次握手、慢启动、占用资源)
- 线头阻塞,一个 TCP 上只能发送一个请求,后续的请求需要排队等待
- 头部冗余,头部未压缩
HTTP2 优点
- 使用二进制进行传输(帧)
- 多路复用,所有通信都在一个 TCP 连接上完成,减少了 TCP 连接数
- 头部压缩(HPACK),客户端和服务端维护一套相同的字典,保存头部 index/key/value,下次传输字节使用 index
- 服务器推送,服务器可主动推送资源给客户端,客户端可以缓存推送的资源,也可拒收。例如推送
index.html的相关静态资源 - 可以通过 RST_STREAM 类型的 frame(帧) 取消某次请求,不必断开 TCP
- 可对每个 stream 设置优先级
安全
XSS(Cross-site scripting)
- 反射型
// name 的值从 url 中获取
// http://www.domain.com?name=<script>alert(1)</script>
<div>{name}</div>
- 存储型
// 评论中注入 script 代码,这样所有浏览的用户都会受到影响
<script>alert(1)</script>
- DOM-based,以上两种都用到了
防御手段
- React 渲染时会自动处理,但是使用
dangerouslySetInnerHTML时��则需要自行转义和过滤 - 外部输入的内容对引号、尖括号、斜杆进行转义
- CSP (设置 HTTP Header 的
Content-Security-Policy)
CSRF(Cross-site request forgery)
关键词: 利用 cookie 利用用户的状态进行恶意请求,在用户不知情的情况下,通过钓鱼网站链接诱导用户请求某些接口。
防御手段
- HTTP 的 Referer 验证请求来源地址
- 请求时附带验证信息,token
- Set-Cookie 中的 SameSite(不能在跨域请求中携带 cookie)/http-only(禁止 JS 访问 Cookie)/secure(只能在 HTTPS 中携带)
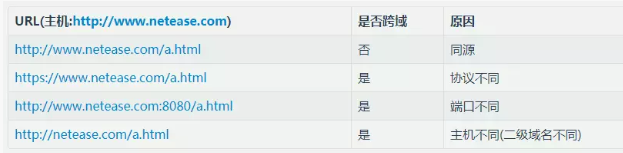
跨域
服务器安全策略,实际请求已发出,非同源请求,均为跨域。名词解释:同源 —— 如果两个页面拥有相同的协议(protocol),端口(port)和主机(host),那么这两个页面就属于同一个源(origin)。
解决方案
- jsonp 通过 script 标签的 src 属性来实现,利用了 script 返回的数据会被浏览器当作 js 执行
<script>
function jsonp(params) {
//这里为上一步定义的全局函数
console.log(params);
}
</script>
<script src="xxx?callback=jsonp"></script>
服务端返回函数 jsonp('response data'),这样客户端接收到后会执行 jsonp
函数,最后打印出数据
- CORS
服务端设置
- Access-Control-Allow-Origin
- Access-Control-Allow-Credentials 运行跨域请求携带凭证(cookie、http 认证和 ssl 证书)
- Nginx 代理
前端服务器 nginx 配置
location /api {
proxy_pass 接口地址;
}
缓存
- 强缓存 (cache-control:max-age/expires)命中的话不会发送请求,cache-control 优先级大于 expires,通过
no-cache每次验证缓存有效性。如果要强制刷新缓存,通过改变资源 url,例如加入版本号。 - 协商缓存(304), 浏览器携带(If-Modified-Since/If-None-Match)询问服务器文件修改时间,服务器对比 (Last-Modified/Etag(服务器优先考虑使用)) 来决定是否返回新的资源
- 存储位置
- service worker,必须是 https,浏览器的独立线程
- memory cache 速度快,容量小,具有时效性(tab)
- disk cache 速度慢,容量大
- push cache http2
- DNS 缓存
- 浏览器
- 系统 hosts
- 路由器
- ISP