Recently, with the release of relevant APIs by OpenAI, more and more AI applications have emerged on the market. The chatpdf project caught my attention. How does it overcome the limitation of the maximum token of the API to read such long texts?
🎉🎉 My new project DocsMind has been open-sourced, supporting Markdown and PDF as well as Docker deployment. Welcome to give it a Star or submit a PR.
Out of curiosity about the chatpdf principle, I started researching relevant applications on the market and wrote a simple demo for learning after a brief understanding, and familiarized myself with the use of OpenAI API.
Demo
In this demo, you can ask ChatGPT questions related to the PDF:
Demo: https://chatpdf-demo.alanwang.site/
Github: https://github.com/3Alan/chatgpt-pdf-demo
The demo is the "GitHub Privacy Agreement" that I ran data in advance. Currently, the Prompt has not been debugged to the best state, so some of the answers to the questions are not very good. You can try asking some simple questions, such as "What personal information is collected in the GitHub privacy agreement?"
Basic principle
- Extract the PDF text for subsequent processing.
- Since OpenAI API has a limit on the number of tokens, we need to split the PDF text into fragments smaller than the token limit.
- Generate vectors for each fragment using OpenAI's Embedding API and save them to the database (Postgres).
- Start to ask questions
- Convert the user's question to a vector.
- Use cosine similarity algorithm to compare the user's question vector with the vectors in the database to find the text fragment that is most similar to the question.
- Feed the text fragment to ChatGPT, let it answer the user's question based on these fragments.
Here we only discuss the general principles. When it comes to actual coding, there are still some issues to consider:
-
How to extract text?
-
What is the dimension for slicing? How can we ensure that each segment is semantically related as much as possible?
Since the extracted PDF text is all in words, we can only slice it by word count and use "sentences" as the dimension for segmentation. Here, we simply use . or 。 as separators for slicing. If it's Markdown, then it's easier - just slice by paragraph so that each segment can be semantically related (in fact, separating semantic tasks is like handing them over to those who write Markdown).
Technology stack used
- PostgresSql
- Next.js
- Supabase: Used to save vectors and text fragments.
Currently, due to the limited frequency of OpenAI API calls, the interface call frequency needs to be controlled when generating vectors for large PDF files.
Proprietary terms
The following are some proprietary terms. After all, I am not a professional AI person. I will post ChatGPT's understanding of these words.
Embedding
Embedding is a technique that converts discrete data (such as words, characters, images, etc.) into continuous vectors. In natural language processing, embedding technology can map words or characters to a low-dimensional continuous vector space, which can better represent semantic information. For example, the two words "cat" and "dog" may be mapped to vectors that are relatively close in the embedding space because they both represent animals, while the two words "cat" and "table" may be mapped to vectors that are relatively far away in the embedding space because they represent different things.
In the ChatGPT PDF project, we use OpenAI's Embedding API to convert PDF text fragments into vectors and save these vectors to the database. The advantage of doing this is that it can better represent the semantic information of text fragments, thereby improving the accuracy of question matching.
Cosine Similarity Algorithm
The cosine similarity algorithm is a method used to calculate the similarity between two vectors. Its principle is to judge the similarity between them by calculating the cosine value of the angle between two vectors.
In the ChatGPT PDF project, we first calculate the cosine similarity between the user's query vector and each text segment vector in the database, and then select the most similar text segment as the context to ask ChatGPT.
How to Run Demo Locally
Please make sure that you can access https://api.openai.com normally.
curl https://api.openai.com
If you receive the following result, it means that you can access it normally. Otherwise, you will need to configure the environment variable OPENAI_API_PROXY to proxy https://api.openai.com.
{
"error": {
"message": "Invalid URL (GET /)",
"type": "invalid_request_error",
"param": null,
"code": null
}
}
Clone Project
- Clone the project
- Create
.envfile and fill in environment variables, see.env.examplefor reference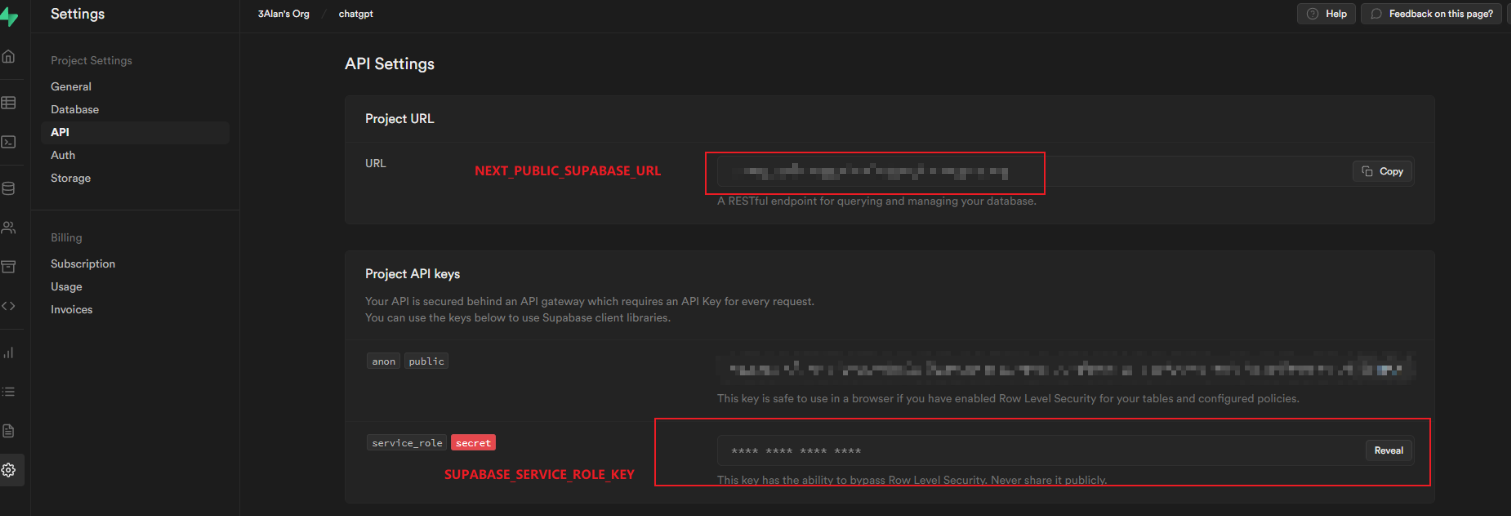
Use Supabase to Create Database
Copy the contents of the schema.sql file in the root directory of the project to Supabase and run it.
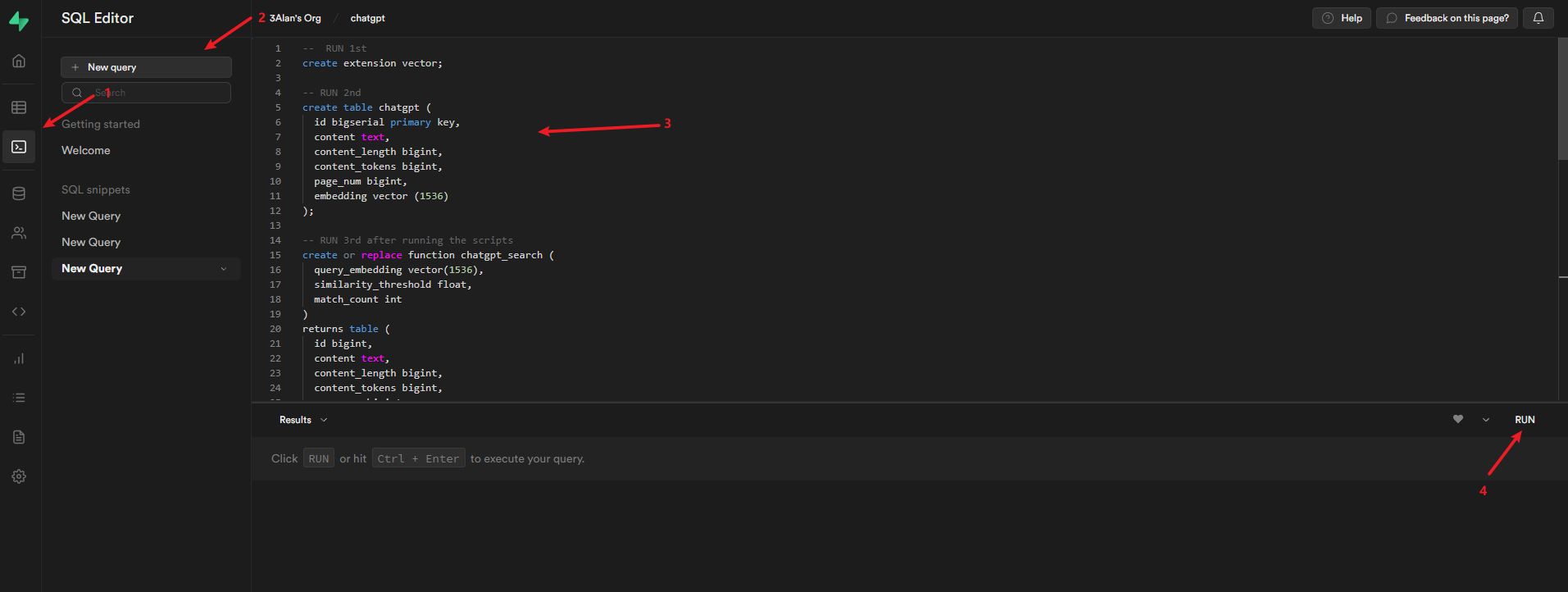
After running, you will get one table chatgpt.
Run Project
yarn
yarn dev
- Delete the pdf that is displayed by default
- Set
disabledUploadto false.
After completing the above steps, you will see
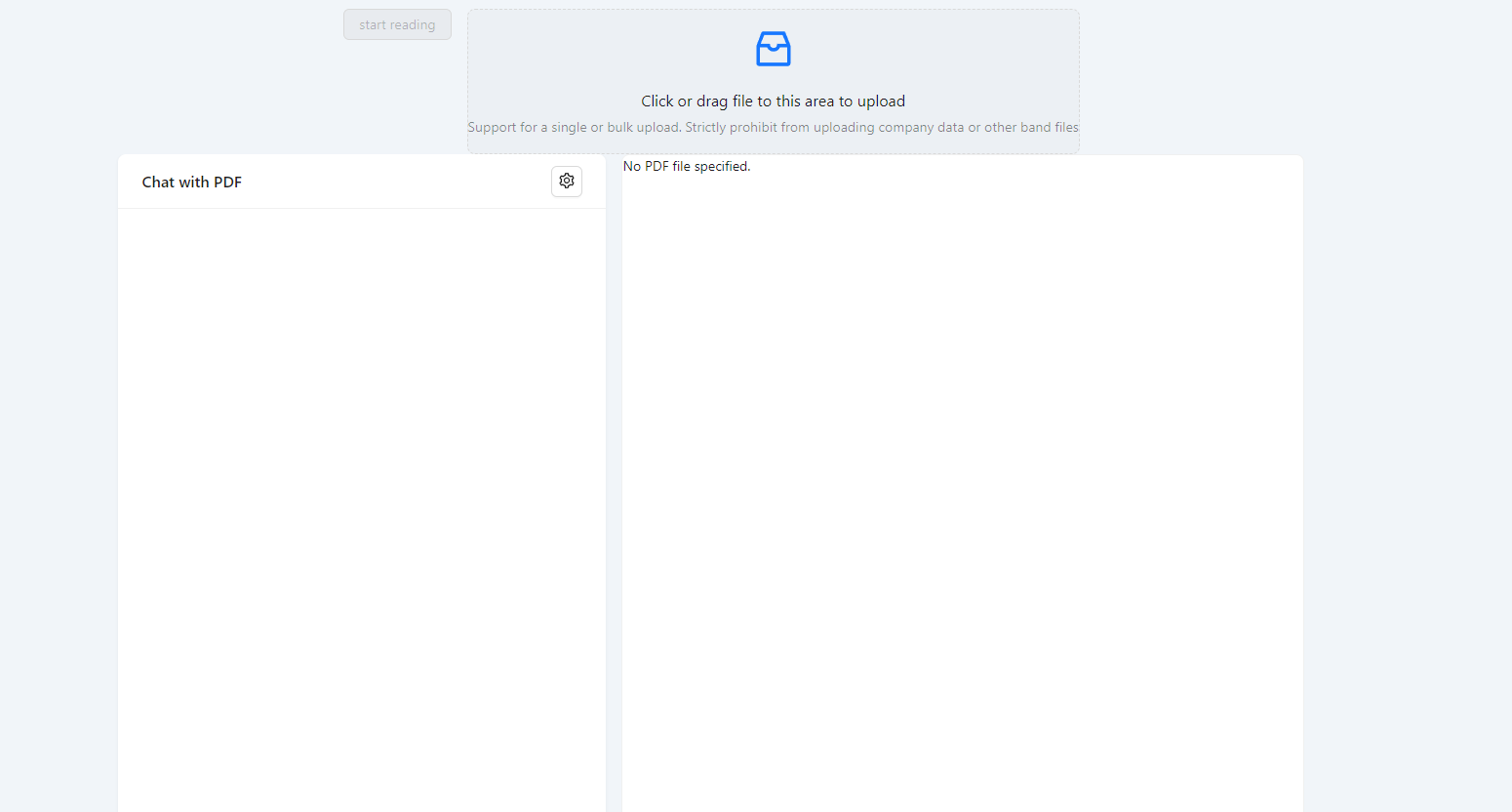
Then upload your PDF and click "Start Reading". This will take some time (depending on the size of your PDF), during which you can view network requests by opening the browser console.
If your file is too large, you may fail due to OpenAI's rate limit.
After the PDF is processed, you will see the embedding values in your Supabase.
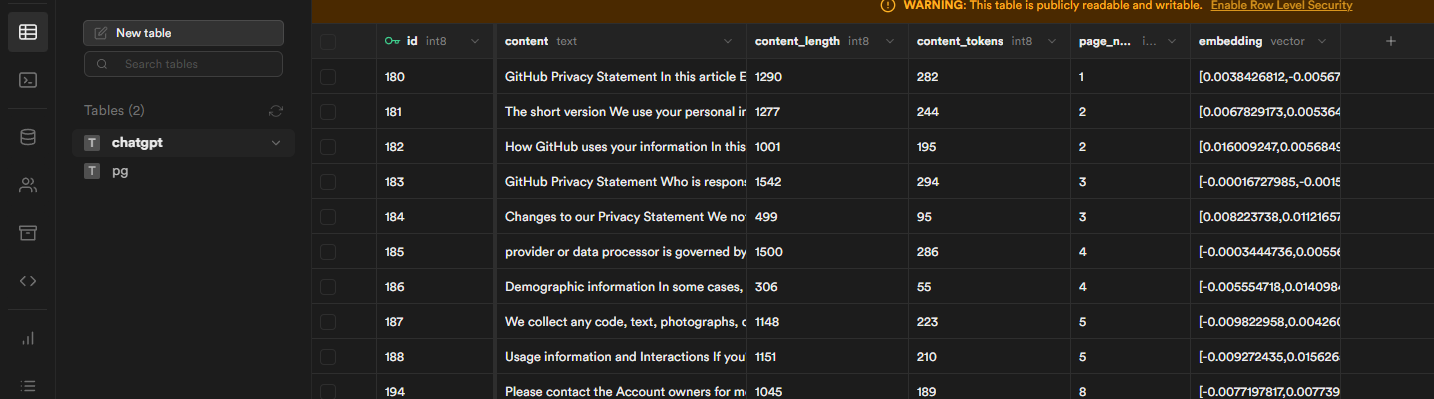
After completing these steps, you can start asking questions. You can fine-tune the prompt to make the answers more accurate.
Adjust PDF Display
After completing the above steps, you can:
- Move your PDF to the public directory
- Change the default displayed PDF to the path of the PDF you uploaded
- Set
disabledUploadto true so that you won't see the file upload module anymore.
Reference
- https://github.com/mckaywrigley/paul-graham-gpt
- https://github.com/openai/openai-cookbook/blob/main/examples/How_to_stream_completions.ipynb
- https://github.com/ddiu8081/chatgpt-demo
If this project inspires you, please give me a star.