最近随着 OpenAI 开放了相关 API, 市面上出现��了越来越多的 AI 应用,chatpdf 这个项目吸引了我的注意,它是如何突破 API 最大 token 的限制来读取这种长文本的呢?
🎉🎉 我的新项目 DocsMind 已经开源了,支持 Markdown 和 PDF 以及 Docker 部署,欢迎 Star 和 PR。
基于对 chatpdf 原理的好奇,我开始研究起市面上相关的应用,于是简单了解后写了个简单的 demo 用于学习,顺便熟悉了下 OpenAI API 的使用。
Demo
在这个 Demo 中,你可以向 ChatGPT 提问 PDF 中的相关问题:
Demo: https://chatpdf-demo.alanwang.site/
Github: https://github.com/3Alan/chatgpt-pdf-demo
Demo 是我提前跑好数据的 "GitHub 隐私协议"。目前 Prompt 还没调试到最佳状态,所以有些问题回答的不算很好。你可以尝试提问一些简单�的问题,例如 "GitHub 隐私协议中有哪些个人信息被收集"。
大致原理
- 提取 pdf 文本,以便后续处理。
- 由于 OpenAI API 对 Token 数量有限制,我们需要将 PDF 文本切分成小于 Token 限制的片段。
- 将每个片段使用 OpenAI 的 Embedding API 生成向量并保存到数据库(Postgres)中
- 开始提问题
- 将用户提出的问题转换为向量。
- 使用余弦相似度算法将用户提出的问题向量与数据库中的向量进行比较,找到与问题最相似的文本片段。
- 将片段文本喂给 ChatGPT,让它基于这些片段回答用户提出的问题。
这里只讲大致原理,具体到代码上还涉及到:
-
如何提取文本?
-
以什么为维度切片?如何尽可能保证每个片段在语义上是相近的?
由于提取出的 PDF 文本都是文字,所以只能以字数来切片,并且以 “句子” 为维度进行切片,这里我们简单的以
。.为分隔符切片。如果是 Markdown 那就简单了,以段落为维度切片,这样就能尽量保障每个片段的语意是相关的(语义分隔的任务其实就相当于交给了写 Markdown 的人)。
使用到的技术栈
- PostgresSql
- Next.js
- Supabase:用于保存向量和文本片段。
目前由于 OpenAI API 调用频率受限,大文件 pdf 在生成向量时需要控制好接口调用频率
专有名词
以下是一些专有名词,毕竟我也不是专业搞 AI 的,我就贴一下 ChatGPT 对这些词的理解
Embedding
Embedding 是一种将离散数据(例如单词、字符、图像等)转换为连续向量的技术。在自然语言处理中,Embedding 技术可以将单词或字符映射到一个低维的连续向量空间中,从而能够更好地表示语义信息。例如,"cat" 和 "dog" 这两个单词在 Embedding 空间中可能会被映射到离得比较近的向量,因为它们都表示动物,而 "cat" 和 "table" 这两个单词在 Embedding 空间中则可能会被映射到离得比较远的向量,因为它们表示的是不同的事物。
在 ChatGPT PDF 项目中,我们使用了 OpenAI 的 Embedding API 将 PDF 文本片段转换为向量,并将这些向量保存到数据库中。这样做的好处是可以更好地表示文本片段的语义信息,从而提高问题匹配的准确率。
余弦相似度算法
余弦相似度算法是一种用于计算两个向量之间相似度的方法。它的原理是通过计算两个向量的夹角余弦值来判断它们之间的相似度。
在 ChatGPT PDF 项目中,我们首先将用户提出的问题向量与数据库中的每个文本片段向量进行余弦相似度计算,然后选择最相似的那个文本片段作为上下文向 ChatGPT 提问。
如何在本地运行 Demo
请确保你能正常访问 https://api.openai.com
curl https://api.openai.com
如果你得到以下结果说明你能正常访问,否则你将需要配置环境变量 OPENAI_API_PROXY 来代理 https://api.openai.com
{
"error": {
"message": "Invalid URL (GET /)",
"type": "invalid_request_error",
"param": null,
"code": null
}
}
克隆项目
- 克隆项目
- 创建
.env文件并填入环境变量,可参考.env.example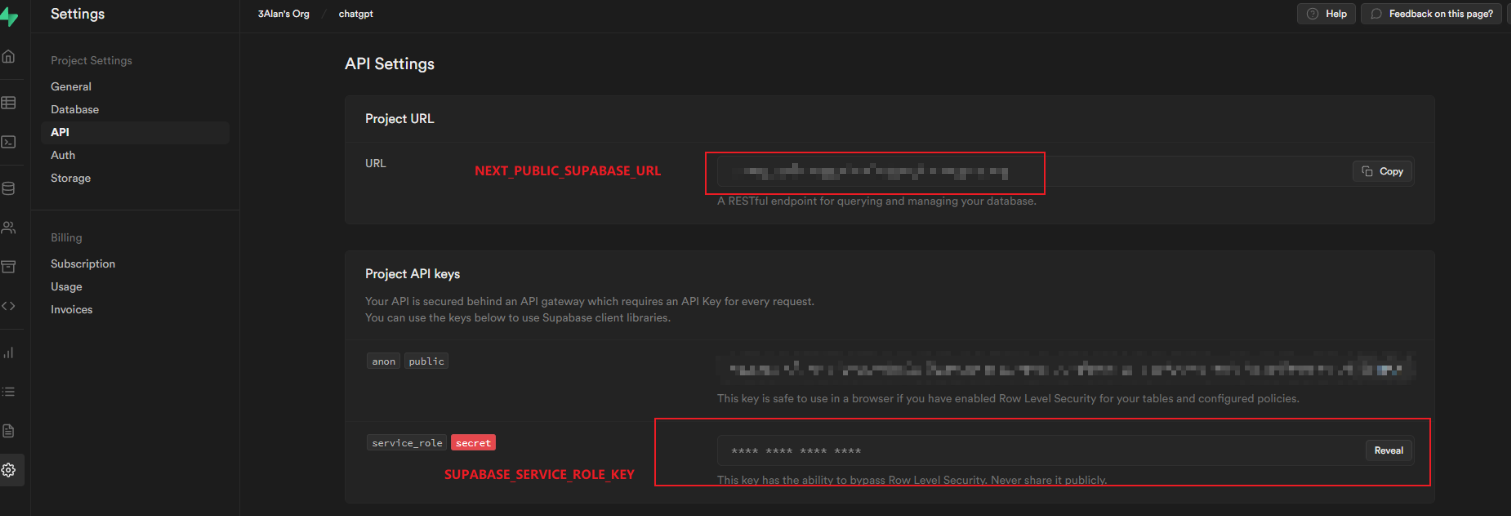
使用 supabase 创建数据库
将项目根目录中的 schema.sql 文件内容复制到 supabase 中并运行
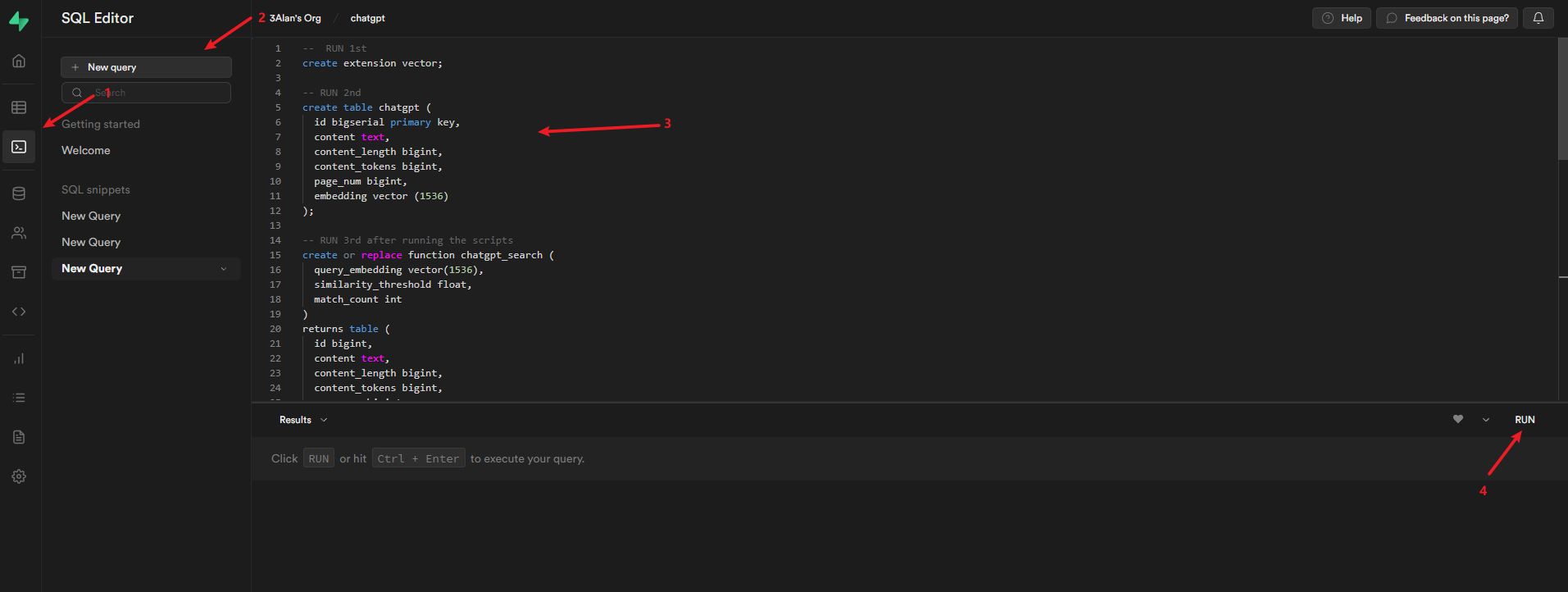
运行完成后你将会得到 chatgpt 表
运行项目
yarn
yarn dev
- 删除默认显示的 pdf
- 修改为
disabledUpload为 false
完成以上步骤后你将看到
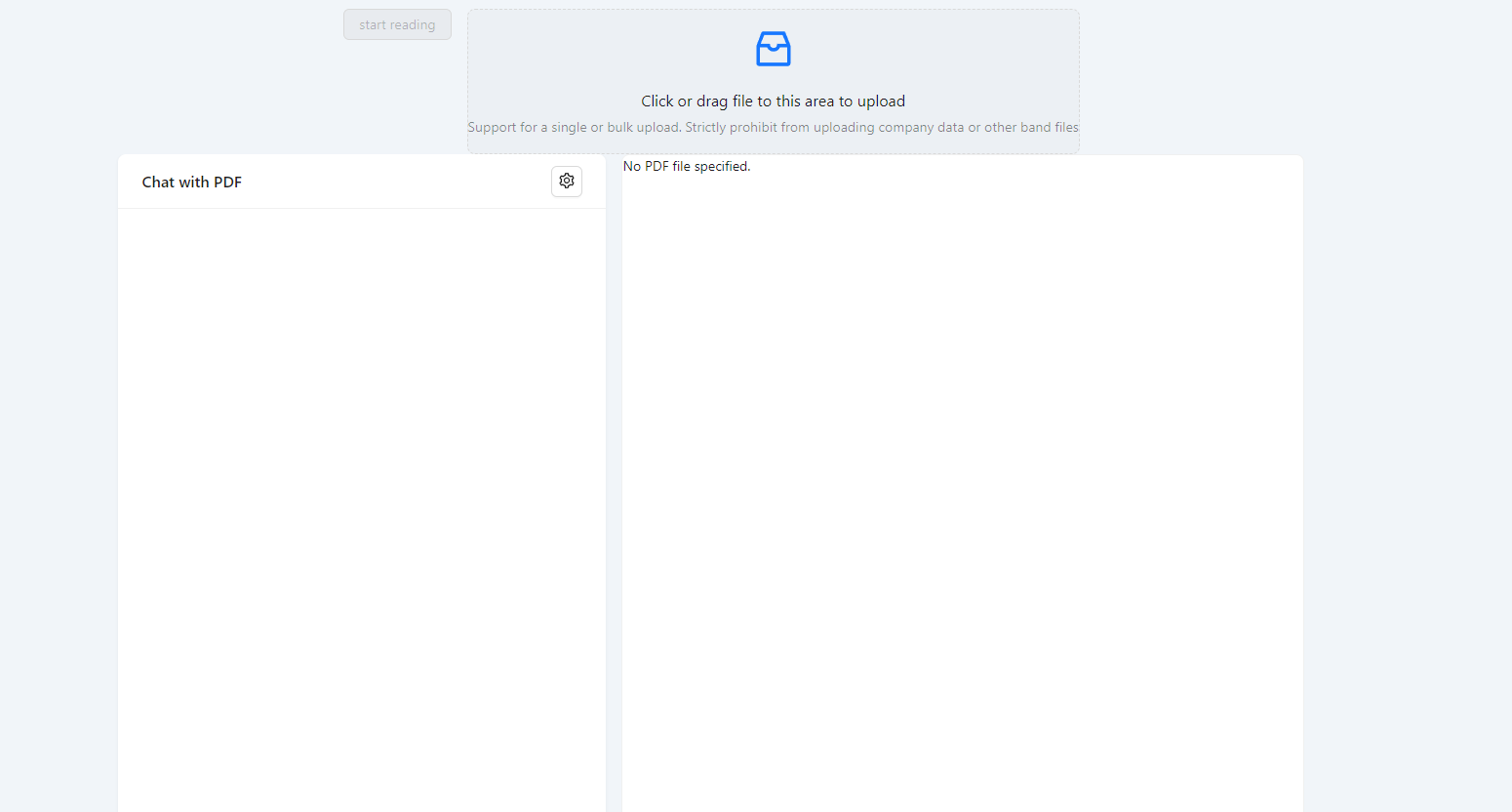
然后上传你的 pdf 并点击 start reading,这将耗费一定的时间(取决于你的 pdf 大小),在这期间你可以通过打开浏览器控制台查看 network 请求。
如果你的文件过大,由于 openai 的 rate limit 你可能失败
pdf ��处理完后,你将在你的 supabase 中看到 embedding 后的值。
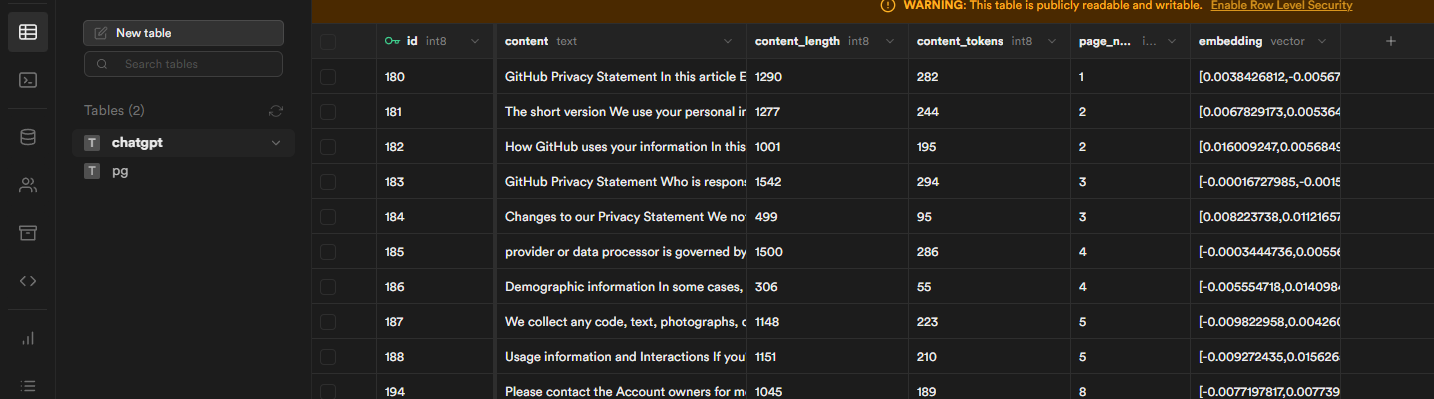
完成这些步骤后你便可以进行提问,你可以通过微调 prompt 来使回答更准确。
调整 pdf 显示
完成以上步骤后你可以:
- 将你的 pdf 移动到 public 目录下
- 将默认显示的 pdf 改成你上传的 pdf 路径
- 修改为
disabledUpload为 true,这样你就不会看到上传文件的模块了
参考资料
- https://github.com/mckaywrigley/paul-graham-gpt
- https://github.com/openai/openai-cookbook/blob/main/examples/How_to_stream_completions.ipynb
- https://github.com/ddiu8081/chatgpt-demo
如果这个项目对你有所启发,不妨给我点个 star 吧